Smarter risk management with AI: how semantic clustering is transforming risk registers
At Inclus, we're always looking for innovative ways to help our clients better understand their risk landscape. That's why we partnered with a team of students from Aalto University, and their findings are genuinely exciting.
A team of Aalto University students has built and tested a semantic risk clustering pipeline that uses AI to automatically group related risks in a risk register — based on meaning, not just keywords. Here's what they found, and what it means for the future of risk management at Inclus.
The challenge: when risk registers become unmanageable
Risk registers are at the heart of qualitative risk management. They capture hundreds, sometimes thousands, of written risk descriptions contributed by multiple stakeholders across an organization. But this creates a real problem: inconsistent formatting, duplicate entries, and sheer volume make it incredibly difficult to see the bigger picture.
Traditional approaches like keyword matching simply don't cut it. They miss the intent behind the words, fail to catch synonyms, and can't identify risks that are closely related but described very differently. We needed something smarter.
The solution: semantic risk clustering
A team of five students from Aalto University's MS-E2177 Seminar on Case Studies in Operations Research (Santeri Paljakka, Essi Nikula, Henrik Purokoski, Jaakko Paavilainen, and Antti Kärkkäinen) took on the challenge of designing and testing a semantic risk clustering pipeline specifically for risk register data.
The core idea is to use Large Language Model (LLM) embeddings to convert risk descriptions into numerical vectors that capture their meaning, not just their keywords. Similar risks then cluster together, even if they are worded completely differently. The pipeline moves through four stages:
Preprocessing – Standardizing raw risk data into clean, structured sentences using an LLM
Embedding – Converting text into high-dimensional vectors that represent semantic meaning
Dimensionality reduction – Compressing those vectors into a more manageable space
Clustering – Grouping similar risks together based on their position in that space
What the testing revealed
The team tested the pipeline across three different risk datasets, including two Inclus mock datasets and the MIT AI Risk Repository (over 1,500 AI-related risks).
On preprocessing, LLM-based standardization helped normalize inconsistent entries and reduced embedding time on larger datasets. However, it didn't dramatically improve clustering quality on its own. When risk descriptions varied significantly in length and style, preprocessing helped produce more consistent clusters.
On embedding models, three top-performing models were tested: F2LLM-v2, Microsoft's Harrier-oss-v1, and OpenAI's text-embedding-3-large. Clustering quality was broadly comparable across all three, but speed was not. The OpenAI API-based model completed the large MIT dataset in around 200 seconds, compared to 600–1,000 seconds for the locally-run alternatives.
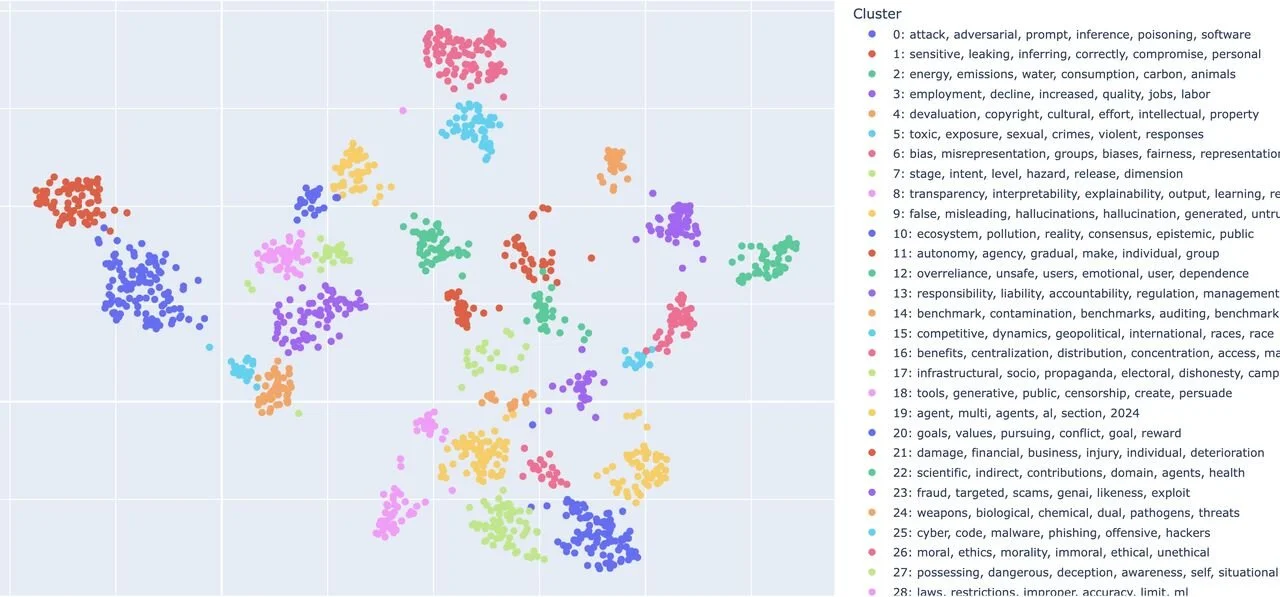
On dimensionality reduction, UMAP consistently outperformed both PCA and no reduction, delivering the highest cluster quality across all datasets and enabling clean 2D visualizations of the risk landscape, while PCA had much faster processing speed. On clustering algorithms, HDBSCAN was the clear winner, achieving significantly higher quality scores than agglomerative hierarchical clustering, particularly on larger datasets. Its key advantage is that it doesn't require pre-specifying the number of clusters, and it can identify genuine outliers, which in risk management could represent rare but critical risks.
Seeing it in action
The qualitative assessment showed that the clusters are genuinely meaningful. On the MIT AI Risk Repository, the pipeline cleanly separated clusters around themes like cybersecurity vulnerabilities and privacy leakage, grouping risks with entirely different wording under the same theme based on shared meaning. This kind of automated organization would take a human analyst days to do manually, and the pipeline does it in seconds.
What's next?
The team identified several directions for further development. Real-time updates would allow new risks to be added without re-running the entire pipeline. Multilingual support would extend the tool to risk registers in Finnish, Swedish, or mixed languages. Combining semantic clustering with knowledge graphs could capture cause-and-effect relationships between risks that share no vocabulary. Finally, a human-in-the-loop interface would let analysts manually adjust clusters based on the current need.
A strong foundation for the future
The pipeline works. The combination of UMAP dimensionality reduction, HDBSCAN clustering, and cosine similarity consistently delivered the best results across all tested datasets. The testing framework and documentation produced by the Aalto team give us a solid foundation to continue developing this capability and integrating it into the Inclus toolkit.
We're grateful to the talented team at Aalto University for their rigorous work, and we're excited about what semantic risk clustering will mean for our customers' ability to understand and manage their risk landscape.
Stay tuned for more updates as we bring this technology to life inside the Inclus platform.